


As the world is becoming more and more reliant on technology, the use of Artificial Intelligence in the workplace has become more relied upon than ever before. The pandemic was a catalyst for a skill set to be developed in a remote fashion and with less in-person contact. The technology industry found a way around this and ensured that good quality training was still delivered, and used artificial intelligence in various different forms to do so. Artificial Intelligence is an umbrella term that is home to different types of machinery which can somewhat align with what is considered human intelligence. Both Deep Learning and Machine Learning come under this umbrella and can be integrated and implemented in a range of different tasks.
Artificial Intelligence can be used to aid productivity, provide training and serve us in an array of different manners. Deep Learning and Artificial Intelligence can be used interchangeably, as can Machine Learning and Artificial Intelligence, but Deep Learning is a type of Machine Learning and they are indeed slightly different concepts. The use of these types of Artificial Intelligence is becoming increasingly more global and used in the everyday workspace.

(Image Source: Statista)
What is Artificial Intelligence?
The use of the term Artificial Intelligence (or AI) is often thrown around in the world of tech and is becoming a piece of jargon that has made its way into everyday conversations. The landscape of artificial intelligence is very much a vast one that is growing and developing continuously.
Artificial Intelligence is the simulation of human intelligence and is processed through the use of machines. It is the amalgamation of a range of different technologies and programmes that work together to act, earn and process with human-like intelligence. It is an umbrella term for a range of programming, which is why it can often not just be narrowed down to one piece of specific technology. Subsets of Artificial Intelligence, such as Deep Learning and Machine Learning highlight the versatility of artificial intelligence and the varying applications it can have.
Artificial Intelligence can mimic human intelligence, to an extent, and uses algorithms to do so. Artificial Intelligence relies on something called a neural network, which is essentially how the human brain operates. An artificial neural network is created to help artificial intelligence function. It is a network that functions using layers of neurons (or instructions and algorithms) which can result in being able to solve problems or process things in a way that mimics human-like intelligence. Deep Learning Neural Networks layers input and output algorithms for artificial intelligence to function as we know it today. Some key examples of artificial intelligence are the use of virtual assistants, such as Siri, Alpha Go and Alexa. They are integrated into everyday life and are of assistance to us as humans in different ways. Researchers within the technology space are still in debate about the access that certain artificial intelligence has to our personal lives and information and what this could mean for the future of artificial intelligence.

(Image Source: Statista)
Artificial Intelligence can be grouped in three different ways and categories, weak artificial intelligence, strong artificial intelligence and general artificial intelligence.
Weak Artificial Intelligence can also be referred to as narrow artificial intelligence and refers to the type of artificial intelligence that is linked and connected to a specific or narrow area. This type of artificial intelligence simulates human cognition, however, isn’t as fully sentient as a human being in terms of emotions and feeling. An example of weak or narrow artificial intelligence is a quick analysis of data that a human being would not be able to process in an equally efficient manner. Although weak and narrow intelligence doesn’t possess the consciousness that human beings and human intelligence possess, it can efficiently process certain data-driven commands quicker and more accurately than human beings could. There are times when weak or narrow artificial intelligence could mimic or simulate the appearance of human consciousness (such as with the virtual assistants), but it inherently cannot do this as a basic function. An everyday example of this type of artificial intelligence is with email spam filters, and being able to detect which emails do not possess the qualities we want to see in our primary inboxes. It is a simple solution to a problem that would probably take a human being more time to sort through that artificial intelligence.
General Artificial Intelligence refers to the potential that artificial intelligence has and its hypothetical potential. This type of artificial intelligence refers to an agent that can learn and acquire knowledge in a way that humans can. It would, hypothetically, be able to produce the same output that a human being could as it would be reflective technology to human actions and behaviour. Take the example of a machine that translates different languages (which is already in existence), it can translate and process a vast amount of languages and data about different languages, but in the instance of general artificial intelligence, it would be able to understand the context of the syntax or the sentence. This is reflective of how a human would process language, it would take into account the situation and meaning of the words.
Strong artificial intelligence is a type of artificial intelligence that would, in theory, mimic the consciousness of human beings. It would cover a larger scope than weak or narrow artificial intelligence. The ability to solve problems and process information would still be primary to this type of artificial intelligence but would be paired with more human-like features and intelligence. Although strong artificial intelligence is still very much in the development phase, various tech-heads have expressed their optimism and positive opinions about strong artificial intelligence. This type of artificial intelligence is still very much in the development phase and stage and more research is needed before it becomes more than just a theoretical concept. At this current time, there are certain tests and methods in place to evaluate how close the intelligence of artificial intelligence is to the intelligence of a human being. The Turing test is a test used to evaluate the intelligence of an artificial intelligence system. It is named so because of mathematician Alan Turing, who founded this test in particular. It is able to test the ability of a machine and the appearance of consciousness that runs parallel to that of a human being.
What is Machine Learning?
Machine Learning is a form of artificial intelligence that can automate the analysis of large amounts of data and focuses on the use of data and algorithms to come up with results. Machine Learning is able to process large and excessive amounts of data and establish decisions based on past and present inputs. It does not necessarily need to be explicitly programmed in the ways that other methods of artificial intelligence may have to be as it is predominantly algorithm and data-based. An example of everyday machine learning is the use of a search engine, such as Google which can extract a result from an extortionate amount of data. Take football players, for instance, you can search for premier league football players and machine learning algorithms will generate a set of structured data from a larger set of data. This in turn is a more efficient way of data pulling than could be done by a human within the speed that machine learning and artificial intelligence do it. Other examples of machine learning include speech recognition, automated stock trading and customer service.
UC Berkeley outlined the three components that typically exist in the algorithm when it comes to machine learning:
A Decision Process: A set of calculations that can establish a pattern and guess what you want from a large set of data.
An Error Function: This is a method of measuring how good the outcome of the decision process was. Was it correct and if not, what can be done to better give an expected result the next time around?
An Updating or Optimisation Process: This is when the algorithm looks at any miss in the error function and learns from this to update itself. From this, the decision process is updated and comes to a final decision to ensure that any future searches that are in a similar realm wield desirable results.
There are three types of machine learning and are classified by the uses and algorithms used. These are:
- Supervised learning
- Reinforcement learning
- Unsupervised learning.
What is Supervised Learning?
Supervised is a type of machine learning that uses a blueprint set of data for models and machines to yield a desired or expected outcome. The data set that is being used when it comes to supervised learning has been pre-labelled and classified, which allows the algorithm to see how accurate the performance of a machine is. Because of this, supervised learning can indeed predict outcomes more and more accurately as it is used more and more, such as with search engines. Supervised learning can be scalable and used in a global space and within organisations (as such with the email sorting).
There are two types of problems that come under supervised learning, which are referred to as classification and regression. Classification uses an algorithm to accurately assign data into specific data sets of categories. It draws conclusions on how data entities should be defined, categorised and labelled. This in turn contributes to the algorithm and allows for accurate results from a large data set and what is commanded of it.
Regression on the other hand is used to evaluate and get to grips with the relationship between dependent and independent variables in a data set. An independent variable is a variable that is manipulated or changed and a dependent variable is a direct effect these changes have on the dependent variable. Regression is often used to make projections and predictions about a data set. For example with a business or company, the use of regression under supervised learning can use patterns established by the data set and project sales revenues or stock needed and not needed. Linear regressions are what is used specifically when calculating the relationship between a single dependent variable and more than one independent variable and is essentially used to make educated and sound predictions about the future outcomes of a data set. This outcome or projection can often be showcased on a graph or in a form of a chart.
What is Unsupervised Learning?
Unsupervised learning, under the realm of machine learning, is the use of a machine learning algorithm that can analyse and sort unlabeled data sets. Unsupervised learning finds hidden patterns or patterned data groupings within its own algorithm, rather than relying on the need for human intervention. The similarities unsupervised learning bears to supervised learning is that there is a mutual ability to find patterns in groups of inputted data and record observations about the patterns found in that data set. Going back to the example of search engines, an incorrect spelling will be a catalyst for suggestions being offered on how to spell it correctly based on past searches.
There is a large range of unsupervised learning, which include, Hierarchical Clustering, Exclusive and Overlapping Clustering and Probabilistic Clustering.
Hierarchical Clustering can also be referred to as hierarchical cluster analysis. This is essentially referring to a cluster or clustering that are initially grouped as isolated data sets. These data sets contain information that allows them to be grouped together because they hold similarities to each other or other parts of the data set. Methods such as average linkage (mean distance between two points in each cluster) and complete linkage (the maximum distance between two points in each cluster) are used to assess the similarities within a data set.
Exclusive and Overlapping Clustering is a form of grouping a data set that can only exist in one cluster. With only one cluster, the way of organising a data set in this way is called exclusive clustering, but when there are multiple degrees of clustering or membership, it is referred to as overlapping clustering. For example, if a data set has one cluster, but different features of the information make it part of other exclusive clusters, this is overlapping. Think of it like a Venn Diagram and overlapping data and features.
Probabilistic Clustering is a form of unsupervised learning that helps to solve soft clustering problems. This is when there are two distinct data sets that overlap and have very subtle similarities and differences. The Gaussian Mixture Model is the main mixture model that classifies data and is mostly used in probabilistic clustering.
What is Reinforcement Learning?
Reinforcement Learning is a type of machine learning where a machine makes a sequence of decisions. It is centred around trial and error and uses this particular operational technique to find a solution. A programmer can reinforce the results that a machine is generating by actioning artificial rewards and penalties for doing the right or wrong action. This reinforcement is what is needed to cement the overall goal of machine learning.
There are, of course, pros and cons to this type of artificial rewards system. A primary positive is centred around automation and the machine trying to maximise the rewards of a certain machine, this could be applied to self-driving cars and maintaining the speed limits, or even streamline the hiring process of a business by bringing people who have the necessary qualifications and attributes required for the role at hand. Some of the challenges that come with reinforcement learning are that the machine has to learn in a simulation environment, which is a more complicated real-life scenario that may not yield recognisable data as the machine experienced in a simulated environment. Reinforcement learning is a time consuming and vigorous type of machine and the test period before being applied to real-life would be extensive.
What is Deep Learning?
Deep Learning is a subset of machine learning and has the goal of making machines reason and think in a similar way to human beings. Deep learning explores how complex machine models can mimic humans and learn new information. Deep learning applies to artificial intelligence as we know it in the form of voice assistant technologies and autonomous driving. Deep learning has the ability to classify many different types of information and is crucial as this type of machine learning has little to no human input when in full use.
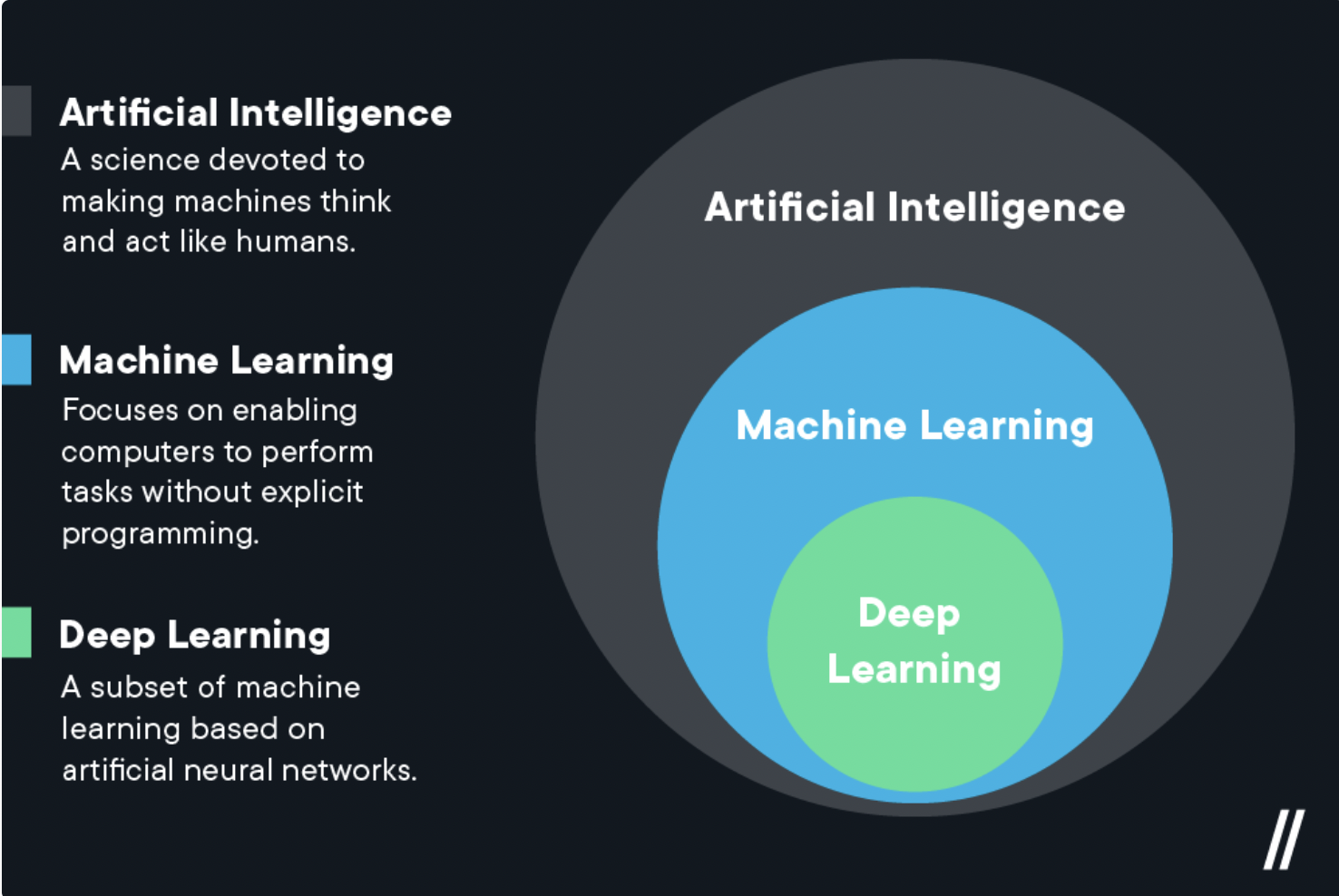
(Image Source: Flatiron School)
Deep Learning is focused on how quickly a machine can learn and develop behaviours without human input and is focused on machines learning new things. Rule-based artificial intelligence, such as deep learning drives how machines operate and function.
The ‘deep’ in deep learning refers to the many layers that the neural network accumulates over time. The neural network is the connections that are made when it comes to referring to this within the world of artificial intelligence. It means that the system analyses data in a specific way, even if the data is uncategorised. The level of accuracy that deep learning can predict can inform the next set of predictions that a system can make.
Training deep learning networks requires a large amount of time and test periods so that the system can refine and make its model more streamlined. Even though it is a subset of machine learning, it goes one step further to establish artificial neural networks and ensure that systems can operate (as best as they can) without human intervention.
What are the main differences between machine learning and deep learning?
Whilst deep learning is machine learning, not all types of machine learning are deep learning. As the examples have outlined and shown both deep learning and machine learning require mass testing and training to ensure that a system yields results that match the functionality of the system.
The aim of machine learning is to give computers the ability to learn with the specific need for constant programming from a human. The algorithms it is based on help and aid a computer to be able to recognise what types of data belong where and for what they are being called. Deep Learning goes one step beyond this and creates hierarchical models that are designed to mirror human intelligence as close as it can. Tapping into the multi-layered neural network, deep learning processes large amounts of data in order to produce a result and analyses the data based on what it already knows. Similar to human intelligence, deep learning bases future decision-making processes on past instruction and outcomes. Further to the standard features of artificial intelligence, deep learning processes data in a simple rule-based manner. Deep learning can be used to identify business outcomes, like fraud detection and improve the operational side of business and warehouses.
There is a range of different sectors that are currently relying on deep learning, including healthcare. The modern-day medical industry is reliant on copious amounts of data. From patient notes to improving the outcomes of patients based on previous data sets and patterns that the system has recognised. Imaging analytics and automating clinical notes are just a few of the ways that deep learning is applied within the medical space and industry.
The public sector is also somewhere that deep learning is applied. From digitising government records to making civil servants more efficient, the use of deep learning navigates the needs of this industry and automates many of the demands that it brings.
The use of artificial intelligence will become more and more prominent in today’s living and the use of machine learning and deep learning will become more of an everyday factor.
Machine learning is able to process data in a way that is significantly more efficient than the methods that humans could use. Taking this to the next level and projecting details about your business using deep learning is also another way that it may be more and more integrated into the future of business and technology.



